深度优先搜索其实就是先序遍历
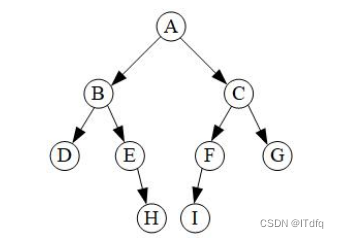
规律是 根左右
将A节点弹出,同时将A的子节点C,B压入栈中,此时B在栈的顶部,stack(B,C);
将B节点弹出,同时将B的子节点E,D压入栈中,此时D在栈的顶部,stack(D,E,C);
将D节点弹出,由于D没有子节点压入,此时E在栈的顶部,stack(E,C);
将E节点弹出,同时将E的子节点H压入,stack(H,C);
将H节点弹出,由于H没有子节点压入,此时C在栈的顶部,同时将C的G,F子节点压入栈中,stack(C,F,G);
...依次往下,最终遍历完成,遍历结果是:A,B,D,E,H,C,F,I,G。package algorithm.list;
import java.util.ArrayList;
import java.util.Stack;
/**
* 深度优先搜索
*
* @author dfq 2022/9/15 14:22
* @implNote 先序遍历 根左右
*/
public class DfSSort {
/**
* 通过递归来实现深度优先搜索
*
* @param root
*/
public void DfsRecursive(TreeNode root) {
if (root != null) {
System.out.println(root.val);
DfsRecursive(root.left);
DfsRecursive(root.right);
}
}
/**
* 通过栈来实现 深度优先搜索
*
* @param root
* @return
*/
public ArrayList<Integer> DfsTree(TreeNode root) {
ArrayList<Integer> lists = new ArrayList<>();
if (root == null) {
return lists;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode tree = stack.pop();
//先往栈中压入右节点,再压左节点,出栈就是先左节点后出右节点了(先序遍历推广)。
if (tree.right != null) {
stack.push(tree.right);
}
if (tree.left != null) {
stack.push(tree.left);
}
lists.add(tree.val);
}
return lists;
}
}
class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}



